Monitorizare
Monitorizare din linia de comandă
În această parte de laborator, se abordează problema monitorizării. Într-o aplicație Docker, se pot monitoriza în primul rând metrici despre mașinile (fizice sau virtuale) pe care rulează serviciile noastre, apoi metrici care țin de containerele care rulează în swarm, și, nu în ultimul rând, metrici care țin de aplicația propriu-zisă și pe care le putem defini.
Cea mai simplă metodă de a monitoriza unul sau mai multe containere este prin intermediul interfeței în linie de comandă din Docker, folosind comanda docker container stats în felul următor:
$ docker container run --name myalpine -it -d alpine
$ docker container stats myalpine
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5d002ad9bba1 myalpine 0.00% 484KiB / 7.774GiB 0.01% 806B / 0B 135kB / 0B 1
În exemplul de mai sus, s-a pornit un container de Linux Alpine, care apoi se monitorizează continuu. Informațiile afișate includ ID-ul și numele containerului, consumul de CPU și memorie, cantitatea de date schimbate pe interfețele de rețea, activitatea pe disc, etc. Dacă se dorește monitorizarea mai multor containere simultan, se poate utiliza comanda docker stats:
$ docker container run --name myalpine2 -it -d alpine
$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
97ab4376c5b7 myalpine2 0.01% 352KiB / 7.774GiB 0.00% 586B / 0B 0B / 0B 1
5d002ad9bba1 myalpine 0.02% 484KiB / 7.774GiB 0.01% 1.02kB / 0B 135kB / 0B 1
În exemplul de mai sus, s-a mai pornit un container adițional. Prin comanda docker stats, se afișează informații statistice despre toate containerele care rulează pe mașină.
Comanda de mai sus poate fi customizată prin formatarea output-ului în funcție de câmpurile care se doresc a fi afișate, precum și modul în care acest lucru este făcut:
$ docker stats --format "{{.Container}}: {{.CPUPerc}}"
97ab4376c5b7: 0.02%
5d002ad9bba1: 0.01%
$ docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}"
NAME CPU % MEM USAGE / LIMIT
myalpine2 0.01% 352KiB / 7.774GiB
myalpine 0.03% 484KiB / 7.774GiB
Dacă se dorește doar afișarea primului rezultat de monitorizare (în loc de o afișare continuă), se poate folosi comanda docker container stats --no-stream.
Monitorizare prin Docker Remote API
Pe lângă comenzile din CLI, Docker oferă și un set de endpoint-uri HTTP remote sub forma unui API, prin care se pot trimite comenzi către daemon-ul de Docker. Printre endpoint-urile din API-ul de Docker, există și câteva care oferă informații mai detaliate de monitorizare:
$ curl --unix-socket /var/run/docker.sock http://localhost/containers/97ab4376c5b7/stats
{
"read": "2022-04-19T08:52:27.9008855Z",
"preread": "0001-01-01T00:00:00Z",
"pids_stats": {
"current": 1,
"limit": 18446744073709551615
},
[...]
"cpu_stats": {
"cpu_usage": {
"total_usage": 51201000,
"usage_in_kernelmode": 14821000,
"usage_in_usermode": 36379000
},
"system_cpu_usage": 18947870000000,
"online_cpus": 4,
"throttling_data": {
"periods": 0,
"throttled_periods": 0,
"throttled_time": 0
}
},
[...]
"memory_stats": {
"usage": 360448,
"stats": {
[...]
},
"limit": 8346984448
},
"name": "/myalpine2",
"id": "97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249",
"networks": {
"eth0": {
"rx_bytes": 936,
"rx_packets": 12,
[...]
}
}
}
Datele sunt generate o dată la o secundă și sunt în format JSON, așa cum se poate observa mai sus (unde s-a formatat JSON-ul pentru a fi urmărit mai ușor, și s-au păstrat doar părți din output, pentru claritate). La rularea comenzii, este necesar ID-ul containerului care se dorește a fi monitorizat.
Monitorizare de evenimente Docker
Dacă se dorește monitorizarea în timp real a unor evenimente Docker ce au loc pe mașina gazdă, se poate folosi comanda docker system events, așa cum se prezintă mai jos:
$ docker system events
# aceste evenimente se generează atunci când oprim containerul myalpine2
2022-04-19T11:57:02.936639300+03:00 container kill 97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249 (image=alpine, name=myalpine2, signal=15)
2022-04-19T11:57:12.977888700+03:00 container kill 97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249 (image=alpine, name=myalpine2, signal=9)
2022-04-19T11:57:13.102094700+03:00 container die 97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249 (exitCode=137, image=alpine, name=myalpine2)
2022-04-19T11:57:13.165242800+03:00 network disconnect 56499229054c04a928960053276ea4bf37c12e575bcdafa522140c835372df62 (container=97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249, name=bridge, type=bridge)
2022-04-19T11:57:13.184247100+03:00 container stop 97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249 (image=alpine, name=myalpine2)
# acest eveniment se generează atunci când ștergem containerul myalpine2
2022-04-19T11:57:19.124295200+03:00 container destroy 97ab4376c5b7e0411abd33277d3ea6ec7e902bdc9af9826d3afe6ff8f9325249 (image=alpine, name=myalpine2)
# aceste evenimente se generează atunci când pornim un container myalpine3
2022-04-19T11:57:40.002873200+03:00 container create fc65cf12a86cf253127415d0b0dabf2399e9dbfa15315c106e3f3566a9b2aee3 (image=alpine, name=myalpine3)
2022-04-19T11:57:40.082728100+03:00 network connect 56499229054c04a928960053276ea4bf37c12e575bcdafa522140c835372df62 (container=fc65cf12a86cf253127415d0b0dabf2399e9dbfa15315c106e3f3566a9b2aee3, name=bridge, type=bridge)
2022-04-19T11:57:40.449862600+03:00 container start fc65cf12a86cf253127415d0b0dabf2399e9dbfa15315c106e3f3566a9b2aee3 (image=alpine, name=myalpine3)
În exemplul de mai sus, s-a pornit monitorizarea de evenimente într-un terminal, iar în celălalt terminal întâi s-a oprit containerul myalpine2 creat anterior, apoi s-a șters, iar în final s-a creat un container myalpine3.
Docker generează notificări pentru evenimente care au loc asupra containerelor, daemonului Docker, imaginilor, rețelelor virtuale, volumelor, etc. Este de asemenea posibilă filtrarea output-ului comenzii de mai sus în funcție de tipul de eveniment căutat, de un anumit container, etc.:
$ docker system events -f event=die -f container=myalpine3
2022-04-19T12:01:22.419370500+03:00 container die fc65cf12a86cf253127415d0b0dabf2399e9dbfa15315c106e3f3566a9b2aee3 (exitCode=137, image=alpine, name=myalpine3)
Monitorizare folosind Prometheus
Prometheus este un toolkit open-source de monitorizare și alertare scris în Go, care colectează metrici prin citirea lor din endpoint-uri HTTP ale componentelor monitorizate (astfel de componente pot fi containere Docker, sau chiar Prometheus însuși). Oferă un model de date multi-dimensional, cu seriile de timp identificate prin-un nume de metrică și perechi cheie-valoare. Componentele monitorizate sunt descoperite prin servicii de descoperire (ca DNS, Consul, etc.) sau prin configurații statice. În plus, Prometheus oferă un limbaj de query funcțional numit PromQL, prin intermediul căruia se pot compune query-uri mai complexe.
În mod implicit, Docker expune metrici pentru Prometheus pe portul 9323, ceea ce înseamnă că o instanță de Prometheus poate monitoriza runtime-ul de Docker de pe un nod.
Această opțiune este încă în stadiu experimental pentru MacOS, așa că este nevoie să se adauge linia "metrics-addr" : "0.0.0.0:9323" în setările avansate de daemon Docker din Docker Desktop.
În general, metricile unei componente care expune date pentru Prometheus se găsesc la un endpoint numit metrics, și așa este cazul și pentru Docker, care expune datele pentru Prometheus la adresa http://localhost:9323/metrics. Acolo se pot observa toate metricile expuse de Docker, iar pașii pentru a vizualiza datele de monitorizare folosind Prometheus sunt descriși în continuare.
Așa cum s-a specificat și mai sus, Prometheus se poate auto-monitoriza. Pentru acest lucru, sunt necesare două componente. În primul rând, este necesar un fișier YAML prin care se setează componentele care se doresc a fi monitorizate, precum și modul în care acestea sunt descoperite pe rețea. Pentru a monitoriza Docker și Prometheus, putem folosi următorul fișier de configurare (pe care îl puteți găsi în repository-ul Configs):
prometheus.yml
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'docker'
scrape_interval: 5s
static_configs:
- targets: ['host.docker.internal:9323']
În fișierul de mai sus, se creează două job-uri de monitorizare:
- unul denumit prometheus, care va colecta date din endpoint-ul HTTP la 5 secunde, de pe interfața serviciului de Prometheus care va fi pornit pe portul 9090
- unul denumit docker, care va colecta date din endpoint-ul HTTP tot la 5 secunde, de pe interfața gazdei Docker pe care se rulează (host.docker.internal se rezolvă la adresa IP internă a gazdei).
Vom rula Prometheus ca un serviciu Docker prin intermediul unui fișier Docker Compose (pe care îl puteți găsi în repository-ul Docker), care arată astfel:
prometheus-stack.yml
version: "3.8"
services:
prometheus:
image: prom/prometheus
volumes:
- ../configs/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
Odată ce facem deployment-ul pe baza acestui fișier de Compose (așa cum am studiat în laboratorul 3), la adresa http://IP:9090/graph se va găsi dashboard-ul Prometheus (prezentat mai jos, unde se pot vedea datele monitorizate și se pot adăuga grafice noi), iar la http://IP:9090/targets se vor găsi componentele monitorizate. De asemenea, ca la Docker, la http://IP:9090/metrics se pot găsi toate metricile generate de Prometheus.
În URL-urile de mai sus, IP se referă la adresa externă a unui nod din cluster-ul Docker (sau localhost, dacă rulăm local).
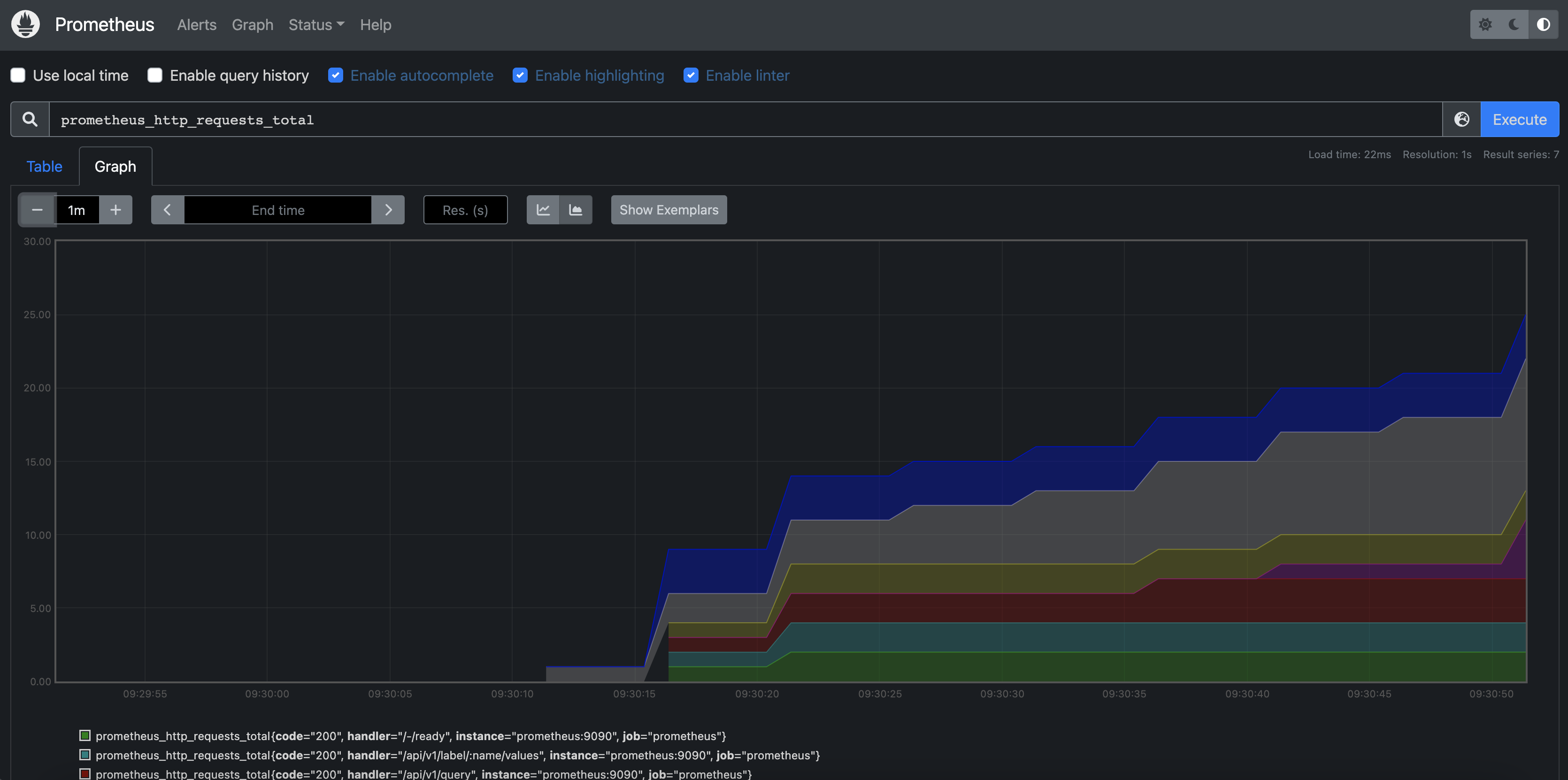
În imaginea de mai sus, s-a ales monitorizarea metricii prometheus_http_requests_total și o reprezentare de tip stacked a datelor, pe un interval de un minut. În textbox-ul de sus, se poate alege metrica ce se dorește a fi afișată (din dropdown-ul de sub el, sau se poate scrie un query în PromQL). Pentru afișare, se apasă butonul Execute, iar vizualizarea poate fi atât în format de grafic (așa cum este prezentat în imaginea de mai sus), cât și la consolă. Se pot adăuga astfel oricâte grafice pe dashboard.
Monitorizarea stării nodurilor
Pentru monitorizarea stării nodurilor care rulează servicii Docker, este necesar ca metricile aferente să fie publicate pe un endpoint HTTP. Pentru acest lucru, se poate folosi componenta Node Exporter din Prometheus, care expune metrici hardware și de sistem de operare de pe mașina gazdă către Prometheus.
Pentru a porni și componenta de Node Exporter pe fiecare nod din cluster, trebuie să adăugăm un serviciu nou în stiva noastră de servicii, rezultând următorul fișier Docker Compose (pe care îl puteți găsi în repository-ul Docker):
prometheus-nexporter-stack.yml
version: "3.8"
services:
prometheus:
image: prom/prometheus
volumes:
- ../configs/prometheus/prometheus-nexporter.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
networks:
- monitoring
node_exporter:
image: prom/node-exporter
deploy:
mode: global
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- 9100:9100
networks:
- monitoring
networks:
monitoring:
Rețeaua comună este necesară pentru că cele două componente (Prometheus și Node Exporter) trebuie să poată comunica între ele pentru a avea acces la date. De asemenea, se poate observa mai sus că serviciul de Node Exporter este rulat în modul global, ceea ce înseamnă ca va rula pe fiecare nod din swarm (pentru a putea exporta metrici de monitorizare pentru fiecare nod în parte). Parametrii de tip mount au rolul de a realiza o mapare între sistemele de fișiere Linux/MacOS de statistici (sysfs și procfs) de pe mașina gazdă și cele din container.
Noul fișier de configurare pentru Prometheus, pe care îl puteți găsi în repository-ul Configs, arată în felul următor:
prometheus-nexporter.yml
global:
scrape_interval: 3s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'docker'
scrape_interval: 5s
static_configs:
- targets: ['host.docker.internal:9323']
- job_name: 'node resources'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- netstat
- job_name: 'node storage'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- filefd
- filesystem
- xfs
Se poate observa că au apărut două target-uri noi, node resources și node storage. Deși ambele iau date din același endpoint, sunt separate într-un mod logic după tipul de date pe care le expun.
Când se face deploy, la adresa http://IP:9090/targets se vor putea observa toate cele patru target-uri (Docker, Prometheus, cele două target-uri noi specifice Node Exporter), iar la http://IP:9090/graph se pot acum alege pentru monitorizare inclusiv metrici generate de Node Exporter.
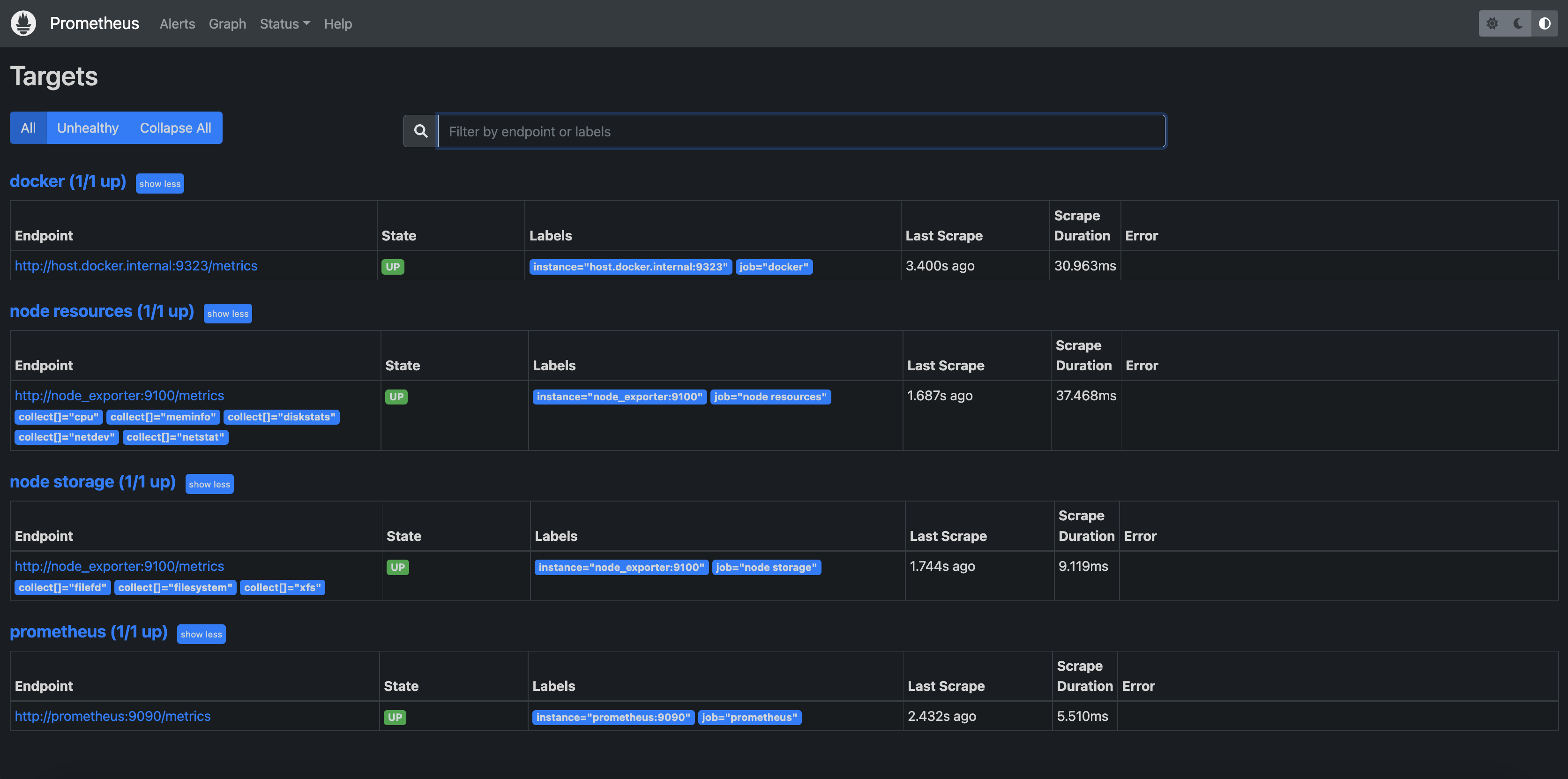
Monitorizare folosind cAdvisor
O altă variantă de monitorizare a mașinilor gazdă și a containerelor este cAdvisor de la Google, care oferă informații de nivel înalt despre CPU și memorie, dar și despre containerele existente. cAdvisor face sampling o dată pe secundă, iar datele sunt ținute un minut (dacă se dorește o stocare de lungă durată, sunt necesare alte servicii).
Pentru monitorizarea folosind cAdvisor, este necesar să se pornească un serviciu de cAdvisor în aceeași rețea cu serviciul de Prometheus și să se adauge target-ul de cAdvisor în fișierul de configurare Prometheus. Noul fișier de configurare, pe care îl puteți găsi în repository-ul Configs, arată în felul următor:
prometheus-nexporter-cadvisor.yml
global:
scrape_interval: 3s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'docker'
scrape_interval: 5s
static_configs:
- targets: ['host.docker.internal:9323']
- job_name: 'node resources'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- netstat
- job_name: 'node storage'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- filefd
- filesystem
- xfs
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
Diferența față de fișierul precedent de configurare este adăugarea target-ului cadvisor. Mai departe, putem face deploy pe baza fișierul Docker Compose de mai jos, pe care îl puteți găsi în repository-ul Docker:
prometheus-nexporter-cadvisor-stack.yml
version: "3.8"
services:
prometheus:
image: prom/prometheus
volumes:
- ../configs/prometheus/prometheus-nexporter-cadvisor.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
networks:
- monitoring
node_exporter:
image: prom/node-exporter
deploy:
mode: global
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- 9100:9100
networks:
- monitoring
cadvisor:
image: gcr.io/cadvisor/cadvisor
deploy:
mode: global
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk:/dev/disk/:ro
ports:
- 8080:8080
networks:
- monitoring
networks:
monitoring:
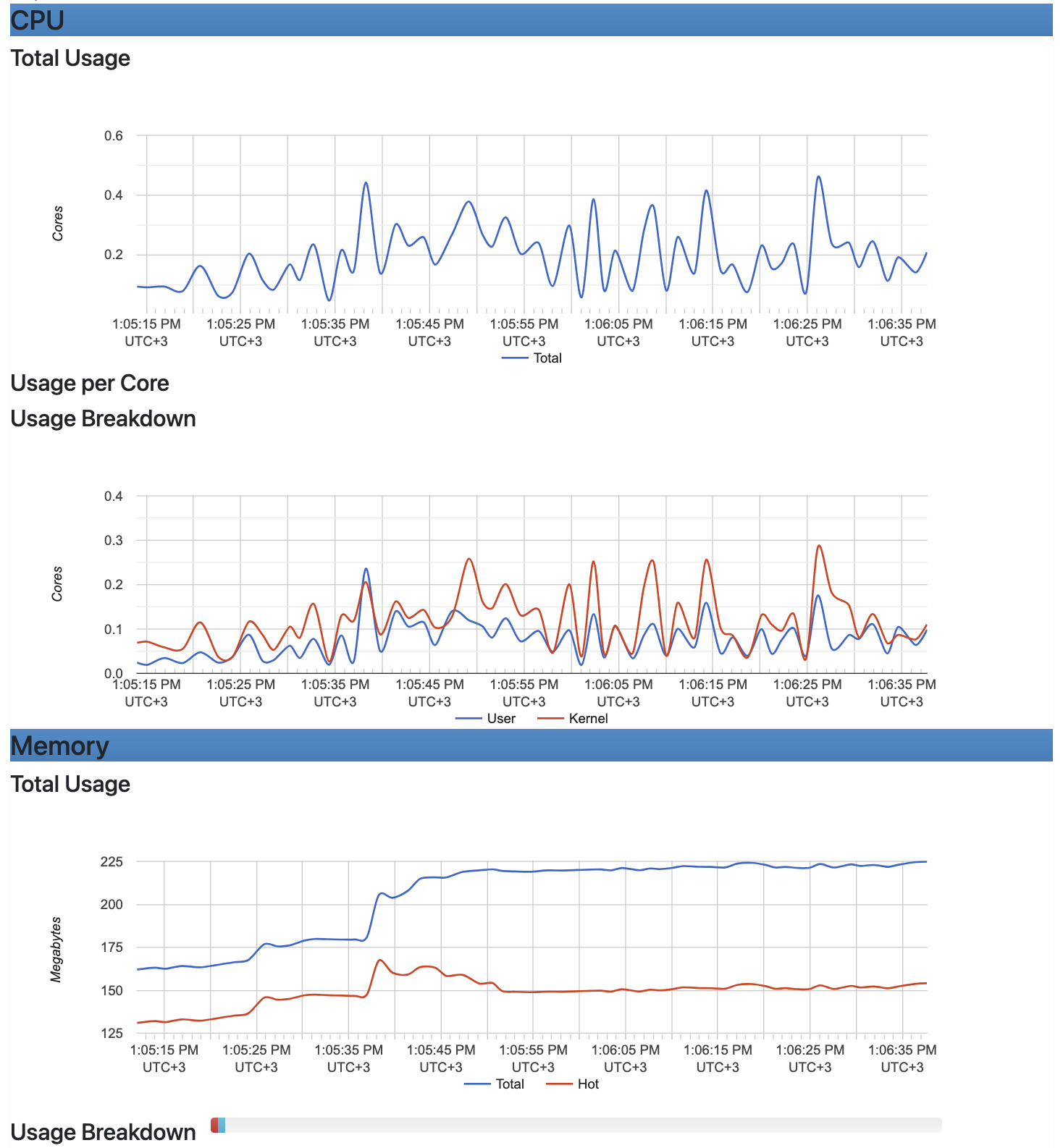
În urma deployment-ului, metricile colectate de cAdvisor vor fi disponibile pentru monitorizare din dashboard-ul de Prometheus. Dacă nu se dorește accesarea din Prometheus, cAdvisor oferă și o interfață Web proprie, care se află la adresa http://IP:8080/, unde se pot regăsi informații despre containerele care rulează (sub categoria /docker), precum și despre utilizarea nodului pe care rulează serviciul, așa cum se poate observa în imaginea de mai jos.
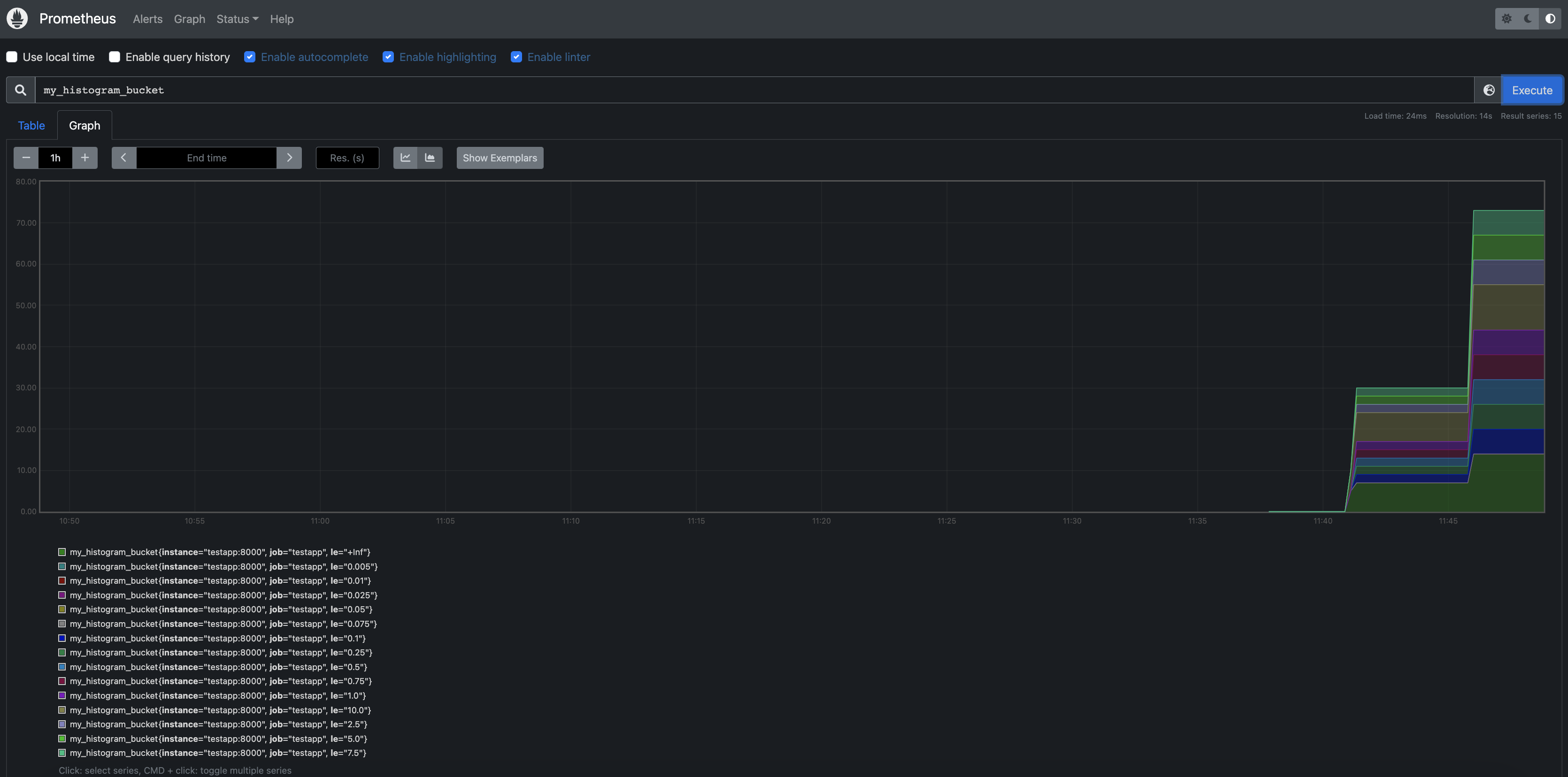
Monitorizarea propriilor aplicații
Până acum, am monitorizat metrici despre nodurile Docker și despre containere, dar nu și despre aplicațiile noastre. Dacă dorim să facem acest lucru, este necesar să exportăm din aplicațiile noastre niște endpoint-uri HTTP care să poată fi citite de Prometheus, exact cum fac toate celelalte componente monitorizate mai sus.
O modalitate de a realiza acest lucru este de a urma documentația oficială Prometheus de instrumentare și de a ne expune direct din aplicații endpoint-ul de metrici cu datele afișate conform specificațiilor. Totuși, acest lucru nu este foarte la îndemână, dar partea bună este că există o serie de biblioteci sau framework-uri care ne ușurează exportarea de metrici, indiferent de limbajul folosit.
În cadrul acestui laborator, exemplificăm monitorizarea propriilor aplicații folosind pachetul prometheus-client în Python. Însă, înainte de a vedea cum se folosește, ar fi util de discutat despre tipurile de metrici acceptate de Prometheus. Astfel, conform documentației oficiale, există patru categorii principale de metrici:
- Counter - un contor unic a cărui valoare poate doar să crească sau să fie resetată la zero
- Gauge - o valoare numerică ce poate urca sau coborî în mod arbitrar
- Histogram - colectează observații (precum durate de cereri sau dimensiuni de răspunsuri) și le numără în bucket-uri configurabile, oferind totodată și o sumă a tuturor valorilor observate
- Summary - similar cu Histogram, dar oferă și cuantile configurabile peste o fereastră dinamică de timp.
Pachetul prometheus-client oferă funcții ușor de utilizat pentru fiecare din tipurile de metrici de mai sus, plus alte câteva auxiliare. Este suficient ca, în aplicațiile din care vrem să exportăm metrici, să instanțiem obiecte specifice tipurilor de metrici și să le actualizăm unde este cazul, și să pornim partea de server care va expune metricile respective pe un endpoint pentru Prometheus. Puteți vedea un exemplu simplu de aplicație Flask care exportă cinci metrici (Counter, Gauge, Histogram, Summary și Info) pe portul 8000 în repository-ul Testapp. Acolo, pe lângă surse, există și un Dockerfile cu ajutorul căruia se poate construi o imagine Docker pentru această aplicație. De asemenea, imaginea se poate găsi deja construită pe Docker Hub cu numele mobylab/idp-laborator4-testapp.
Aplicația din laborator rulează și un server web care poate primi cereri de tip POST pe portul 5000 pentru a genera date legate de metricile oferite, astfel:
- inc_counter - crește valoarea metricii de tip Counter
- inc_gauge - crește valoarea metricii de tip Gauge
- dec_gauge - scade valoarea metricii de tip Gauge
- set_gauge - setează valoarea metricii de tip Gauge (cu un parametru numit value)
- set_summary - setează valoarea metricii de tip Summary (cu un parametru numit value)
- set_histogram - setează valoarea metricii de tip Histogram (cu un parametru numit value).
Pe partea de deployment, este necesar să adăugam aplicația noastră într-o rețea comună cu Prometheus, rezultând următorul fișier Docker Compose, pe care îl puteți găsi în repository-ul Docker:
prometheus-nexporter-cadvisor-testapp-stack.yml
version: "3.8"
services:
prometheus:
image: prom/prometheus
volumes:
- ../configs/prometheus/prometheus-nexporter-cadvisor-testapp.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
networks:
- monitoring
node_exporter:
image: prom/node-exporter
deploy:
mode: global
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- 9100:9100
networks:
- monitoring
cadvisor:
image: gcr.io/cadvisor/cadvisor
deploy:
mode: global
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk:/dev/disk/:ro
ports:
- 8080:8080
networks:
- monitoring
testapp:
image: mobylab/idp-laborator4-testapp
ports:
- 8000:8000
- 5000:5000
networks:
- monitoring
networks:
monitoring:
Din punct de vedere al fișierului de configurare pentru Prometheus, trebuie adăugat un job pentru aplicația noastră, pe portul 8000, rezultând următorul fișier, pe care îl puteți găsi în repository-ul Configs:
prometheus-nexporter-cadvisor-testapp.yml
global:
scrape_interval: 3s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'docker'
scrape_interval: 5s
static_configs:
- targets: ['host.docker.internal:9323']
- job_name: 'node resources'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- netstat
- job_name: 'node storage'
static_configs:
- targets: ['node_exporter:9100']
params:
collect[]:
- filefd
- filesystem
- xfs
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
- job_name: 'testapp'
static_configs:
- targets: ['testapp:8000']
Odată ce s-a făcut deployment-ul, putem observa la http://IP:9090/targets și noul target, pe care putem apoi face query-uri din pagina de grafice, așa cum se poate observa în imaginea de mai jos.