ForkJoinPool Class
Another method to implement the Replicated Workers model in Java is the Fork/Join framework, which uses a "divide et impera" approach, meaning it first involves the recursive splitting (Fork) of the initial task into smaller, independent subtasks until they are small enough to be executed asynchronously. After that, the recursive collection (Join) of results follows to produce a single result (in the case of a task that doesn't return a specific result, it simply waits for all subtasks to finish execution).
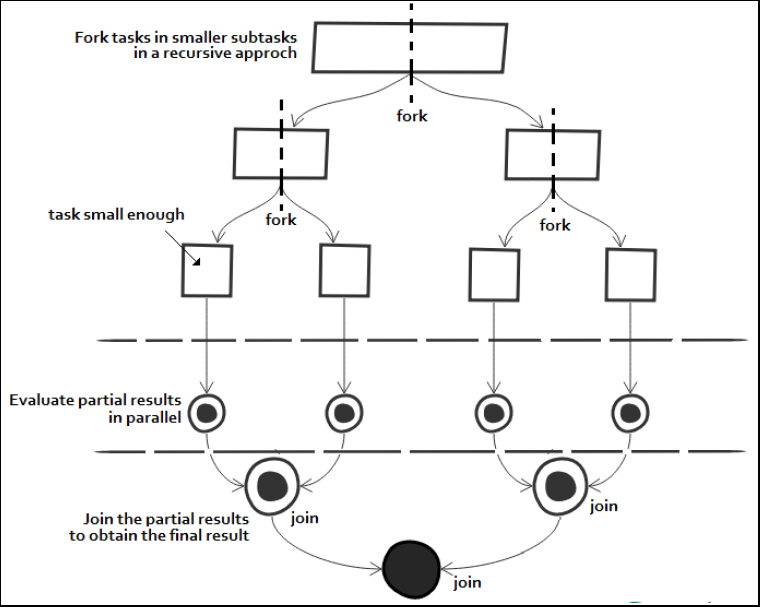
For efficient parallel execution, the Fork/Join framework uses a thread pool called ForkJoinPool, which manages worker threads of type ForkJoinWorkerThread. ForkJoinPool is an implementation of ExecutorService that manages worker threads, each capable of executing a single task at a time. In its implementation, each thread has its own task queue, but when it becomes empty, the worker can "steal" tasks from another worker's queue or from the global pool of tasks.
A task to be executed using the Fork/Join framework can be defined in two ways, depending on the return value. If the task doesn't need to return anything, it is defined by inheriting the RecursiveAction class. If the task returns a value of type V, then it should inherit the RecursiveTask<V> class to define a task. Both parent classes have a method called compute() where the logic of a task is defined (equivalent to the run() method in ExecutorService).
To add tasks that need to be executed by workers, you can use the invoke() method, which creates a task and waits for its result, or a combination of the fork() and join() methods. In the second case, the fork() method sends a task to the pool but doesn't mark it for execution; this is done explicitly through the join() method. Both invoke() and join() return a value of type V for a RecursiveTask.
Since, in the case of a task that doesn't return anything, you can use RecursiveTask<V>, we present a complete implementation example below that uses RecursiveTask for the same problem as in the ExecutorService example.
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class Example2 {
public static void main(String[] args) {
ForkJoinPool fjp = new ForkJoinPool(4);
fjp.invoke(new MyTask("files"));
fjp.shutdown();
}
}
class MyTask extends RecursiveTask<Void> {
private final String path;
public MyTask(String path) {
this.path = path;
}
@Override
protected Void compute() {
File file = new File(path);
if (file.isFile()) {
System.out.println(file.getPath());
return null;
} else if (file.isDirectory()) {
File[] files = file.listFiles();
List<MyTask> tasks = new ArrayList<>();
if (files != null) {
for (File f : files) {
MyTask t = new MyTask(f.getPath());
tasks.add(t);
t.fork();
}
}
for (MyTask task : tasks) {
task.join();
}
}
return null;
}
}
In the example above, both ways of creating and submitting a new task for execution can be observed. In the main() method, invoke() is used, which will block until all tasks have finished, ensuring that it's safe to call shutdown(). On the other hand, within a task, all tasks are added using fork(), and their completion is awaited using join().