Laboratorul 7 - Modelul Replicated Workers
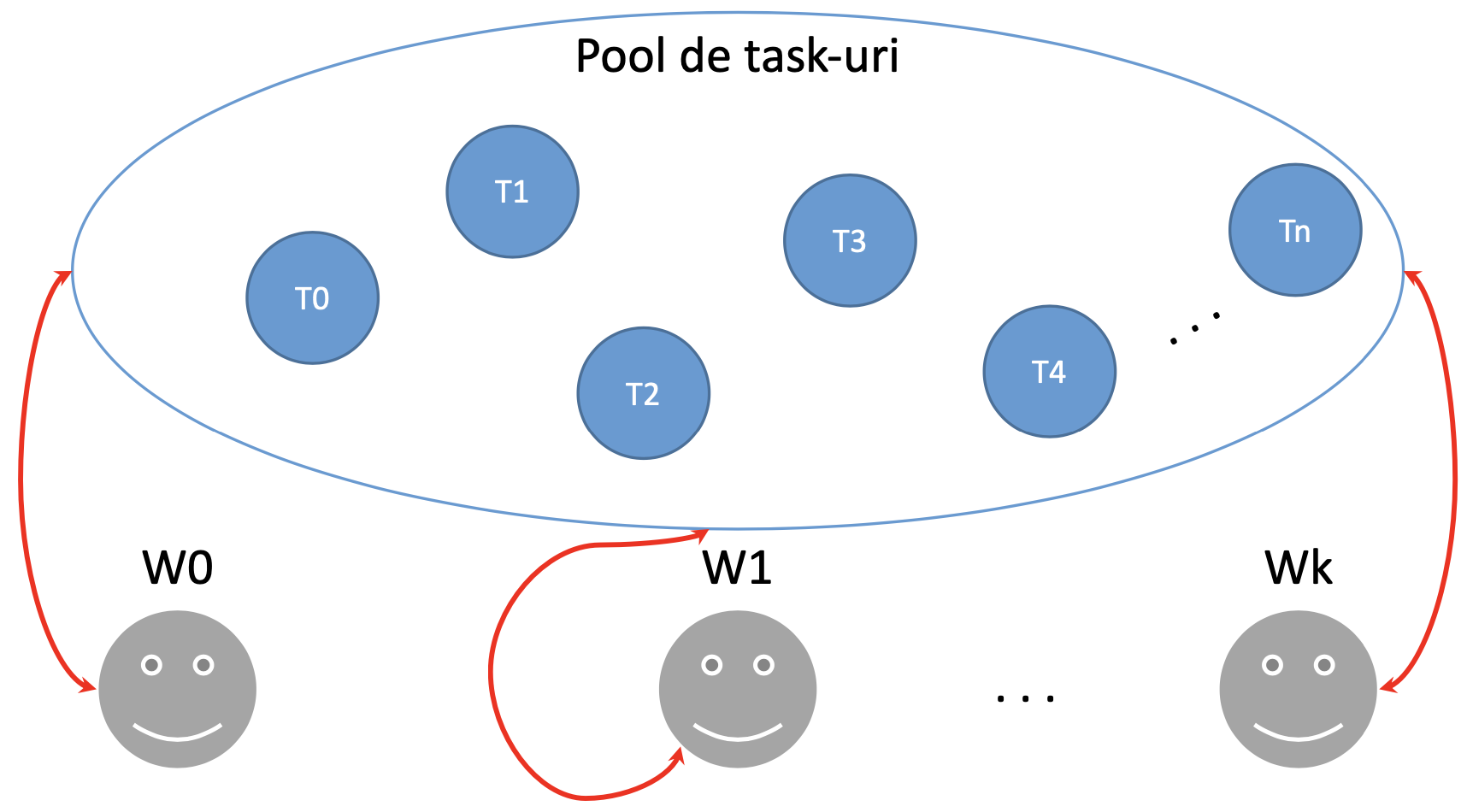
În programarea paralelă, modelul Replicated Workers (sau Thread Pool) este un design pattern folosit pentru obținerea de concurență în execuția unui program. În acest model, există două componente principale: un pool de sarcini de executat (task-uri), reprezentat în general ca o coadă, și un grup de workeri (care sunt în general thread-uri). Fiecare worker din modelul replicated workers are următorul comportament:
while (1)
ia un task din pool
execută task-ul
adaugă zero sau mai multe task-uri rezultate în pool
Așa cum se poate observa în pseudocodul de mai sus, un worker ia un task din pool și îl execută. Ca urmare a execuției unui task, este posibil să se genereze task-uri adiționale, pe care worker-ul le adaugă în pool, după care repetă pașii precedenți.
Modelul Replicated Workers este util atunci când:
- nu se cunoaște în avans dimensiunea problemei, adică numărul de pași care se vor executa
- există multe task-uri de dimensiuni mici care trebuie executate și este mai eficient să se refolosească aceleași thread-uri decât să se creeze unele noi la fiecare pas
- există posibilitatea ca thread-urile să fie dezechilibrate (de exemplu, unele core-uri sunt mai ocupate, sau chiar diferite între ele, și o împărțire egală a sarcinilor de calcul ar duce la întârzieri în program).
O reprezentare grafică a modelului replicated workers poate fi observată în figura de mai jos.
📄️ Obiectiv și studiu de caz
În cadrul acestui laborator, vom utiliza modelul Replicated Workers și vom studia și utiliza mai multe interfețe Java care permit implementarea acestui model care poate fi folosit inclusiv pentru paralelizarea algoritmilor descriși ca funcții recursive.
📄️ Interfața ExecutorService
ExecutorService este o interfață în Java ce permite executarea de task-uri asincrone, în background, în mod concurent, pe baza modelului Replicated Workers. De exemplu, putem avea nevoie să trimitem un număr de cereri, dar ar fi ineficient să le trimitem pe rând, secvențial, așteptând după fiecare să se termine. Soluția ar fi să lucrăm asincron, adică să trimitem o cerere, să nu așteptăm "după ea" (deci să se trimită în background) și să folosim thread-uri pentru a împărți numărul de cereri și a trimite mai multe deodată (concurent). Acesta ar fi cazul când nu știm în avans dimensiunea problemei pe care o rezolvăm, și fie avem nevoie de toate soluțiile problemei (pentru că trebuie să trimitem toate cererile), fie nu vrem să găsim toate soluțiile, ci minim una.
📄️ Clasa ForkJoinPool
O altă metodă de a implementa modelul Replicated Workers în Java este framework-ul Fork/Join, care folosește o abordare divide et impera, ceea ce înseamnă că întâi are locul procesul de împărțire (Fork) recursivă a task-ului inițial în subtask-uri independente mai mici, până când acestea sunt suficient de mici cât să poată fi executate asincron. După aceea, urmează partea de colectare recursivă a rezultatelor (Join) într-un singur rezultat (în cazul unui task care nu returnează un rezultat propriu-zis, pur și simplu se așteaptă ca toate subtask-urile să se termine de executat).
📄️ Exerciții
În acest laborator, veți lucra cu acest schelet, pe care îl veți utiliza să paralelizați trei probleme pe baza modelului Replicated Workers, folosind ExecutorService și ForkJoinPool: