Clasa ForkJoinPool
O altă metodă de a implementa modelul Replicated Workers în Java este framework-ul Fork/Join, care folosește o abordare divide et impera, ceea ce înseamnă că întâi are locul procesul de împărțire (Fork) recursivă a task-ului inițial în subtask-uri independente mai mici, până când acestea sunt suficient de mici cât să poată fi executate asincron. După aceea, urmează partea de colectare recursivă a rezultatelor (Join) într-un singur rezultat (în cazul unui task care nu returnează un rezultat propriu-zis, pur și simplu se așteaptă ca toate subtask-urile să se termine de executat).
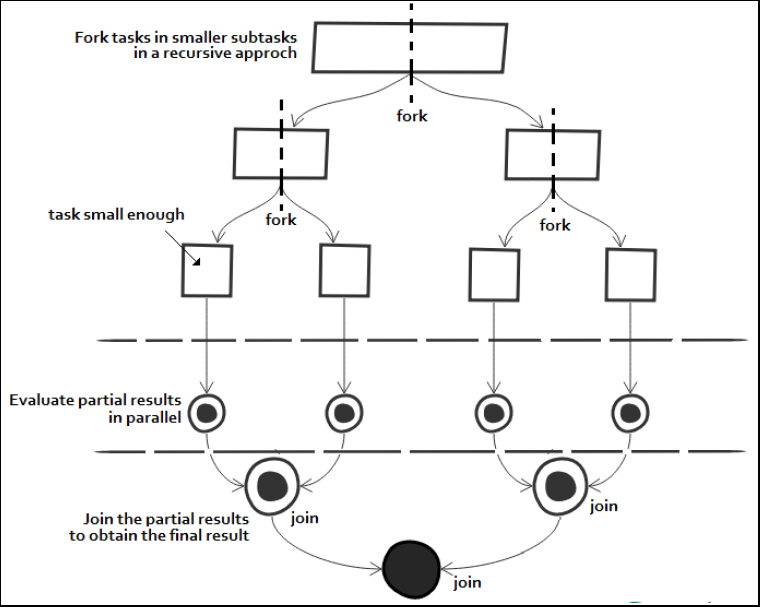
Pentru o execuție paralelă eficientă, framework-ul Fork/Join folosește un pool de thread-uri numit ForkJoinPool, care gestionează thread-uri worker de tipul ForkJoinWorkerThread. ForkJoinPool este o implementare de ExecutorService care gestionează thread-uri de tip worker, care pot executa câte un singur task la un moment dat de timp. În implementarea sa, fiecare thread are propria sa coadă de task-uri, dar, atunci când aceasta se golește, worker-ul poate să "fure" task-uri din coada altui worker sau din pool-ul global de task-uri.
Un task care va fi executat folosind framework-ul Fork/Join poate fi definit în două moduri, în funcție de valoarea de retur. Dacă task-ul nu trebuie să returneze nimic, un task se definește prin moștenirea clasei RecursiveAction. Dacă task-ul returnează o valoare de tip V, atunci trebuie să se moștenească clasa RecursiveTask<V> pentru definirea unui task. Ambele clase părinte au o metodă numită compute() în care se definește logica unui task (echivalentul metodei run() de la ExecutorService).
Pentru a adăuga task-uri care trebuie executate de workeri, se poate folosi metoda invoke(), care creează un task și îi așteaptă rezultatul, sau combinația de metode fork() și join(). Pentru al doilea caz, metoda fork() trimite un task în pool, dar nu îl marchează spre execuție, acest lucru făcându-se explicit prin intermediul metodei join(). Atât invoke(), cât și join(), returnează o valoare de tipul V pentru un task de tip RecursiveTask.
Pentru că, în cazul unui task care nu returnează nimic, se poate folosi RecursiveTask<V>, prezentăm mai jos un exemplu complet de implementare care folosește RecursiveTask, pentru aceeași problemă ca în exemplul de ExecutorService.
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class Example2 {
public static void main(String[] args) {
ForkJoinPool fjp = new ForkJoinPool(4);
fjp.invoke(new MyTask("files"));
fjp.shutdown();
}
}
class MyTask extends RecursiveTask<Void> {
private final String path;
public MyTask(String path) {
this.path = path;
}
@Override
protected Void compute() {
File file = new File(path);
if (file.isFile()) {
System.out.println(file.getPath());
return null;
} else if (file.isDirectory()) {
File[] files = file.listFiles();
List<MyTask> tasks = new ArrayList<>();
if (files != null) {
for (File f : files) {
MyTask t = new MyTask(f.getPath());
tasks.add(t);
t.fork();
}
}
for (MyTask task : tasks) {
task.join();
}
}
return null;
}
}
În exemplul de mai sus, se pot observa ambele moduri de a crea și submite spre execuție un task nou. În main(), se folosește invoke(), care se va bloca până când toate task-urile s-au terminat, deci până este sigur să apelăm shutdown(). În schimb, în interiorul unui task, se adaugă toate task-urile folosind fork(), și apoi se așteaptă finalizarea lor folosind join().